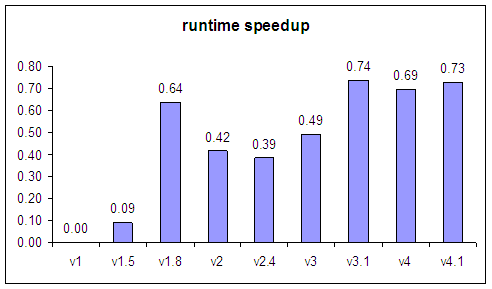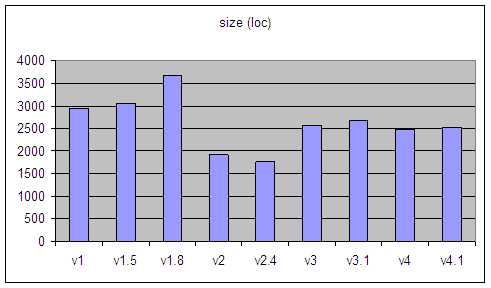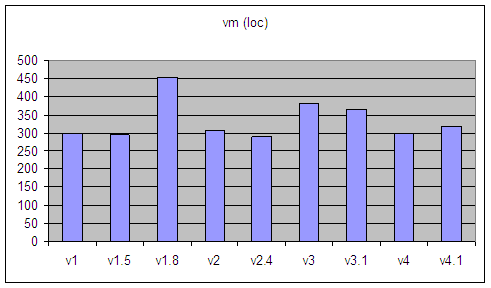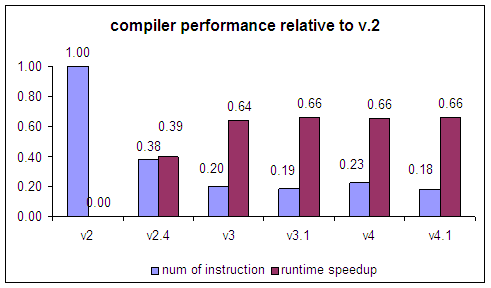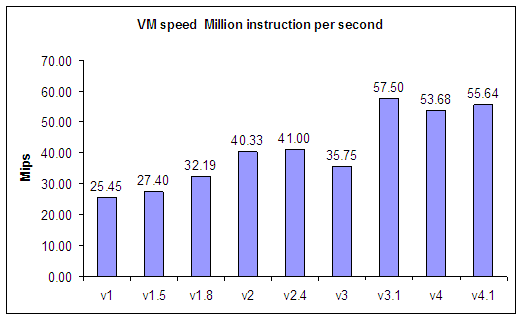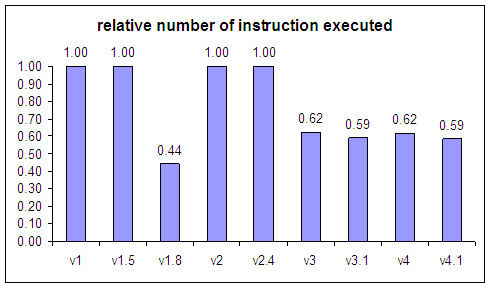
| 4 Dec 2004 | som-v1 | first public release |
| 31 Dec 2004 | som-v2 | second public release, with som-in-som |
| 26 June 2005 | som-v1.5 | with macro and tail-call |
| 5 Jan 2006 | som-v1.7 | with new VM, T-code |
| 23 Dec 2006 | som-v1.8 | bug fixed v 1.7, T-code |
| 12 Jan 2007 | som-v2.4 |
(som-in-som for 2007) Children-day release |
| 9 Mar 2007 | som-v3 | som-in-som with sx-code vm |
| 19 Aug 2007 | som-v3.1 | fast sx-code vm |
| 2 July 2008 | som-v4.0 | fast u-code vm |
| 9 Aug 2008 | som-v4.1 | (improve u-code and compiler) Birthday release |