
Big Data เป็นคำที่ฮิตติดปากในช่วงนี้ นักคอมพิวเตอร์น้อยคนนักที่จะไม่เคยได้ยิน และถ้าดูรายละเอียดของระบบ Big Data จะพบว่ามีความหลากหลายมาก ไม่ว่าจะเป็นเรื่องของ Map-Reduce หรือ NoSQL รวมไปถึง In-Memory Computing จนทำให้เกิดความน่าหนักใจในการติดตามเทคโนโลยีนี้ไม่น้อย
แต่ไม่ว่า Big Data จะซับซ้อนเพียงไร สถาปัตยกรรมของ Big Data ก็มาจากพื้นฐานที่สำคัญคือคำว่า Scale-Out โดยปกติแล้วคำในกลุ่มนี้จะเป็นการออกแบบสถาปัตยกรรมให้สามารถประมวลผลได้มากขึ้น รองรับข้อมูลที่ใหญ่ขี้น ซึ่งมีอยู่ 2 คำคือ Scale-Up กับ Scale-Out โดย Scale-Up จะเป็นการที่เราหาเครื่องคอมพิวเตอร์ หรืออุปกรณ์ที่มีขนาดใหญ่ขึ้น หรือมีทรัพยากรที่มากขึ้น นำมาประมวลผลทดแทนเครื่องเดิม เพื่อทำงานได้เร็วขึ้น หรือรองรับข้อมูลที่ใหญ่เพิ่มขึ้นนั่นเอง
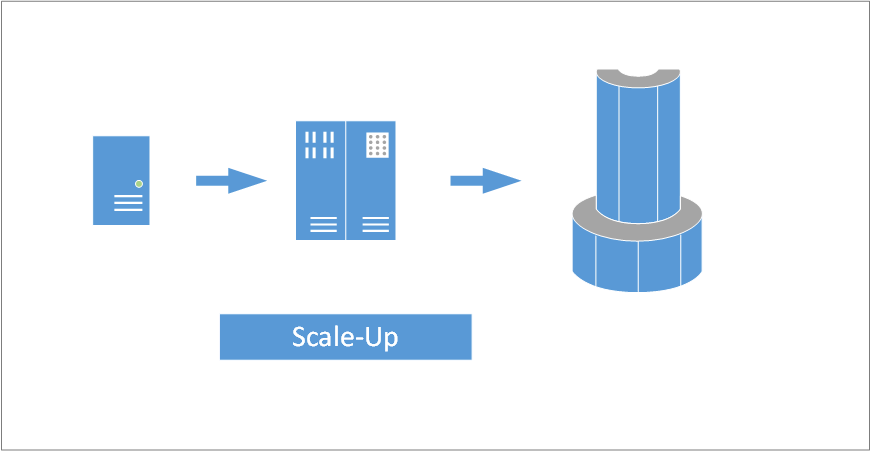
รูปแบบ Scale-Up เป็นรูปแบบที่ทำได้ง่าย เพราะสามารถใช้ระบบงานที่มีอยู่เดิมได้เลย โดยไม่ต้องไปปรับเปลี่ยนให้ยุ่งยาก คือขอให้มีสตางค์ซื้อเป็นอันทำได้แน่ๆ แต่ก็ยังมีข้อจำกัดอยู่ที่ระบบที่ขยายขึ้นนั้น จะไม่สามารถใหญ่เกินกว่าเครื่องที่มีประสิทธิภาพสูงสุดเพียง 1 เครื่องเท่านั้น ซึ่งเวลาเราเอ่ยถึง Big Data เราพูดถึงข้อมูลขนาดหลักหลาย Terabytes จนถึงระดับ Petabytes กันเลยทีเดียว คงเป็นไปไม่ได้ ถ้าจะใช้ Scale-Up เป็นหลักการทำงานพื้นฐานของ Big Data
ส่วนคำว่า Scale-Out เป็นการเอาเครื่องจำนวนมากมาช่วยกันทำงาน มีการกระจายข้อมูลต่างๆไปไว้ในเครื่องต่างๆ โดยข้อมุล 1 ชุดอาจจะกระจายไปหลายเครื่องพร้อมๆกันเพื่อช่วยกันทำงาน โดยคาดหวังว่าการแบ่งงานกันทำ จะทำให้ระบบทำงานได้มีประสิทธิภาพมากยิ่งขึ้น ฟังแล้วก็เข้ากันกับ Big Data มากๆ เพราะอยากรองรับข้อมูลใหญ่ขึ้นเท่าไหร่ ก็หาเครื่องมาเพิ่ม เพื่อทำงานร่วมกับเครื่องที่มีอยู่เดิม แต่เอาเข้าจริงมักจะไม่เป็นอย่างที่คิด เพราะการนำเอาเครื่องจำนวนมากมาช่วยกันทำงานจำเป็นที่จะต้องแก้ปัญหาหลายข้อ เช่น การที่ข้อมูลมีการผูกพันธ์เป็นกลุ่มก้อนทำให้เกิดการแบ่งข้อมูลไปช่วยกันทำได้ยาก หรือการที่จะต้องระวังว่าถ้ามีการเปลี่ยนแปลงข้อมูลเกิดขึ้น เครื่องทุกเครื่องที่มีการใช้ข้อมูลนั้นอยู่จะต้องรับทราบการเปลี่ยนแปลงนั้นเหมือนๆกัน ไม่งั้นอาจจะเกิดข้อผิดพลาดได้
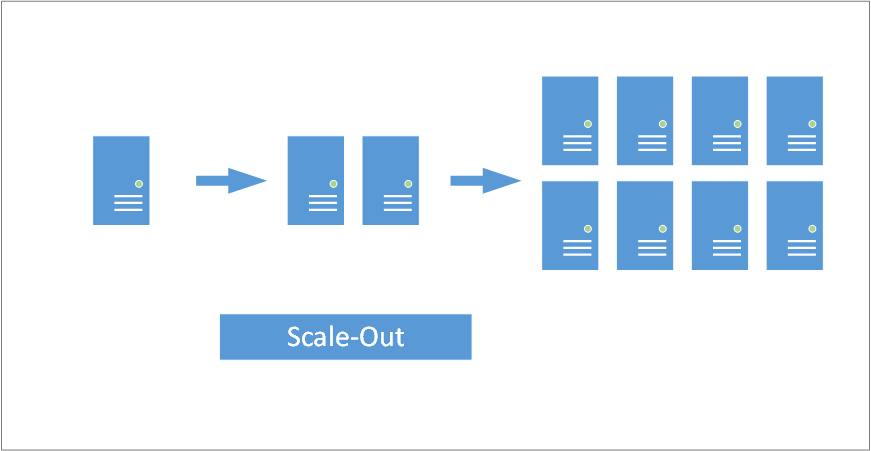
เพื่อแก้ปัญหานี้ ระบบงาน Big Data หลายระบบงานจึงต้องมีการตั้งข้อสมมุติฐานบางอย่างเพื่อให้ระบบสามารถทำงานในแบบ Scale-Out ได้ อาทิเช่น ระบบ NoSQL จะไม่มีการรองรับการเก็บข้อมูลแบบ Relational เพื่อลดความผูกพันธ์ข้อมูลในก้อนต่างๆ เพื่อให้สามารถกระจายข้อมูลในรูปแบบ Scale-Out ได้ดี หรือระบบ HDFS ของ Hadoop ที่มีแนวความคิดว่าข้อมูลที่ใช้ ไม่มีการเปลี่ยนแปลง ดังนั้น จะถูกกระจายออกไปซ้ำๆกันกี่ชุดก็ได้ อยู่ที่ไหนก็ได้ เป้นต้น
จะเห็นได้ว่า จริงๆแล้วหลักการของสถาปัตยกรรมของ Big Data ก็มาจากพื้นฐานความคิดง่ายๆอย่าง Scale-Out เพียงแต่มีการปรับโจทย์หรือตั้งข้อสมมุติฐานต่างๆ เพื่อให้สามารถทำ Scale-Out ได้นั่นเอง