CogSci 108b Lecture Notes
The idea of a "heuristic" is a technique which sometimes will work,
but not always. It is sort of like a rule of thumb. Most of what we
do in our daily lives involves heuristic solutions to problems. They
usually work, or they usually work well enough, an when they don't
work, we then deal with that.
We often use the word "heuristic" not just to describe cases where a
solution might not be found, but to describe cases where we want to
find the best solution (according to some way to measure bestness). A
heuristic might help us to find solutions which are good, but perhaps
not the very best they can be. This is the idea of heuristics that we
will talk about today. Obviously the measure of goodness, and the
assessment of a heuristic technique, is going to be relative to the
domain, and to the specific job that problem solving is going to be
applied to in that domain.
As an example of a heuristic, consider the problem of driving across
the country. If you think of each city as a "state" in this problem
domain, and each highway connecting cities as an "operator" that can
be applied, we can treat this problem in terms of the model of a
problem space.
Suppose that for some reason you are in Omaha, Nebraska and you are
driving to Boston, Massachusetts. You have to choose which highway to
take out of town. Here is a map of your options (from MapBlast):
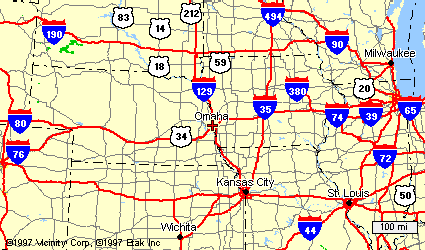
If you were to apply Breadth-First search to this problem, you would
consider all of the highways out of Omaha, and then consider all of
the highways from the places they lead to. So you would consider I-80
going east towards Illinois and west towards the I-76 junction. You
would consider I-29 going north towards Sioux City, as well as going
south towards Kansas City. From Kansas City, you would consider I-70
towards St. Louis, as well as east, heading into Kansas. At each city
or junction, you would consider all of the possible ways to go from
there. Clearly you will spend a lot of time considering stupid routes.
A Depth-First search might be even worse - you might end up
considering roads out of Denver before any of the ways around Chicago.
Clearly what you want to do in this case is to consider roads that at
least head north or east, that go roughly towards Boston. This is a
heuristic because it might be the case that you will have to choose
roads sometime that don't go directly towards your goal. For example
when you get to Chicago you will have to head south for a while, to
get around Lake Michigan. Still it is a lot better than heading into
South Dakota.
Suppose that instead of knowing that Boston is north and east of
Omaha, you know the distance from each city in the country to Boston.
You have the following information:
| Omaha to Boston: | 1463 miles |
| Kansas City to Boston: | 1437 miles |
| Wichita to Boston: | 1627 miles |
| Chicago to Boston: | 1015 miles |
| Souix City to Boston: | 1570 miles |
This table can help you decide which route to choose. Clearly it
doesn't make a lot of sense to head towards Wichita or Souix City,
given that they are both further from Boston than Omaha is. Heading
to Kansas City gets you a bit closer, but if you take I-80 to Chicago,
you will be much closer.
So another heuristic in the driving domain is to choose the highway
that takes you to the city that is closest to your goal. Again this
won't always work, and for the same reasons: mountains and lakes and
canyons and tornadoes can make what might otherwise seem to be the
shortest route less attractive.
This last heuristic for the driving domain is the basic idea behind
most "heuristic search" techniques in artificial intelligence. If you
can somehow estimate which states are "closest" to a goal state, using
some numerical measure of closeness, this estimate can be used to
decide which states to consider applying operators to next.
So the general idea of a heuristic search can be illustrated with this
modified version of the general search algorithm:
states = make_empty_bag ()
add_to_bag (initial_state, states)
loop:
if is_empty (bag) FAIL
else:
state = remove_from_bag (bag)
if achieves_goal (new_state) SUCCEED
for each op in operators:
if op_applies (op, state)
new_state = apply_op (op, state)
add_to_bag (new_state, states)
sort_states_by_heuristic_value ()
After the new states are added to the bag, the contents of the bag are
sorted so that those states for which the heuristic estimate of the
distance to the goal is lowest are near the front. The state with the
lowest estimate distance will be at the front and will be the next
state removed from the bag and have operators applied to it.
In fact, sorting the entire contents of the bag is not always
necessary. One could also implement the remove_from_bag
operator to find the state whose heuristic estimate is lowest and
remove that one from the bag.
If the states are sorted by the heuristic estimate to the goal, as
just described, and the one for which the estimate is smallest is the
one chosen to be expanded, the search that results is sometimes called
"Best-First Search". In some ways it is similar to Depth-First search
in that it will tend to expand states that are the result of states
that it has expanded before, but in this case the choices are driven
by the estimate of the distance to the goal. Best-First search is
good for domains (like driving in the Midwest) when a direct path to
the goal is almost always possible.
A simplification of Best-First Search is called "Hill Climbing". The
idea here is that you don't keep the big list of states around - you
just keep track of the one state you are considering, and the path
that got you there from the initial state. At every state you choose
the state that leads you closer to the goal (according to the
heuristic estimate), and continue from there.
The name "Hill Climbing" comes from the idea that you are trying to
find the top of a hill, and you go in the direction that is up from
wherever you are. This technique often works, but since it only uses
local information, it can be fooled.
Consider hiking in a dense fog. If you can only see a few feet around
you, you couldn't tell whether you are at the top of the biggest hill,
or on some other, shorter, peak, like this fellow:
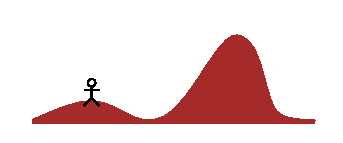
The smaller peak is an example of a "local maxima" in a domain (or
"local minima" if, as in the discussion above, we seek the state with
the lowest heuristic value).
Hill climbing search works well (and is fast, and takes little memory)
if an accurate heuristic measure is available in the domain, and if
there are now local maxima.
Best-First search can fall into the same traps as Hill-Climbing, but
can get out of them, because it keeps track of the other states. So
it may be fooled for a while and head towards local minima or maxima,
but it will ultimately back out of them and head towards the global
goal.
Both best-first search and hill-climbing search are best when it is
important to find a solution fast --- not necessarily to find the best
solution. As we have seen, Breadth-First search, while slow, is
guaranteed to find a solution with the smallest possible number of
operators.
In some cases it is desired to find a solution that minimizes some
other measure of the "cost" of a solution other than just the number
of operators in the sequences. For example, each operator could take
a different amount of time, and we want to find the fastest solution,
or the operators have literal costs, like if you want to buy a set of
components for a new stereo or computer. In the driving domain, it is
often desired to find a route that takes the minimum time, or covers
the least total distance, not necessarily the one that travels on the
smallest number of different roads.
To see how to design a search to find the minimum cost solution to a
problem, consider a different way to implement Breadth-First search.
Suppose that instead of the queue idea discussed in the last lecture,
we use the sorting algorithm described above, except that the
heuristic value that we use to sort the states is equal to the number
of operators that were applied to get to them.
If we sort the states this way, we will have all of the states that
are in, for example, level 1 of the tree sorted before any of the
states that are in level 2, and so forth. But that means that the
requirements for a search to be a Breadth-First search are satisfied.
Now sorting the list of states to implement a Breadth-First search is
sort of a waste, because the queue idea allows for much faster
implementation, but it leads to a simple generalization of
Breadth-First search that will find the minimal cost solution with any
cost measure:
The "heuristic" value associated with each state is the total cost of
the sequence of operators that led to the state. If we sort the
states according to this value, we will be guaranteed to examine
states in such a way that the first solution we find will be the
solution with the minimum cost.
To see why this is true, suppose that the minimum cost is
Cmin. Since states are sorted according to their cost, and
since (we assume) each operator has either a zero or positive cost, we
will examine every state with cost Cmin before we examine
any state with any greater cost. Since, by assumption, the minimum
cost solution has cost Cmin, we will find it before any
solution with a higher cost.
This approach to finding solutions with minimum cost has the same
problems as Breadth-First search: It is not "guided" towards the goal
at all. It is as likely to examine paths on the road to goal states
as it is likely to waste its time examining totally irrelevant paths.
A search technique that finds minimal cost solutions and is also
directed towards goal states is called "A* (A-star) search". (The
"star" comes from the notation that the inventors of this technique
used when they described it. I think that their typewriter didn't
have many options.)
To see how A* works, consider using the following quantity as the
heuristic value H(state) for a given state:
H(state) = Cost(state) + Estimate(state)
Where:
Cost(state) = actual cost incurred in reaching the state
Estimate(state) = estimate of cost needed to get from state to goal
In Best-First search and Hill Climbing, the estimate of the distance
to the goal was used alone as the heuristic value of a state. In A*,
we add the estimate of the remaining cost to the actual cost needed to
get to the current state.
To prove that A* search will find the minimal cost solution, if one
exists, we need to show that it will consider the solution with the
minimal cost before it considers any states with higher cost. If this
can be proved, then it follows that A* will find the lowest cost
solution.
Suppose, as above, that the minimal cost solution has cost
Cmin. We need to show that A* will only examine states
with cost less than Cmin before it examines any with
greater cost. In the following diagram, I have shown two sequences of
states in a search space. One, involving the states S1 and S2, is, we
shall assume, the minimal cost solution, and has cost Cmin.
The other, involving the states S3 and S4, has some other cost,
Calt, which is greater than Cmin, and has not
yet found a solution.
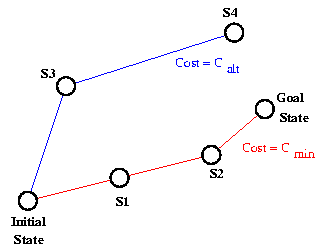
We need to prove that state S2 will be expanded before any state like
S4, whose cost is greater than the cost of the minimal solution.
To assure that this will happen, it must be the case that:
Cost(S4) + Estimate(S4) > Cost(S2) + Estimate(S2)
But we know that the cost of S4 is Calt, so this would mean
that:
Calt + Estimate(S4) > Cost(S2) + Estimate(S2)
We assumed that Calt > Cmin, so if it is the
case that
Cost(S2) + Estimate(S2) <= Cmin
then there is no way that state S4 could be expanded before S2 is, no
matter what value that Estimate(S4) has (even if it is zero).
Let us use Actual(state) to represent the actual distance from state
to a goal. For state S2, we know that:
Cost(S2) + Actual(S2) = Cmin
So to ensure that state S2 will be expanded before any states that
would led to a more costly solution, it is necessary to have a way to
estimate the distance to the goal such that:
Estimate(state) <= Actual(state)
That is: The heuristic estimate of the distance from the state to the
goal must be less than or equal to the actual minimal distance from
that state to the goal. If it is, then A* search is guaranteed to
find the minimal cost solution.
One way that Estimate(state) could be less than Actual(state) would be
if Estimate(state) is always zero. In that case we have the minimal
cost based search described above. It too will find the minimal cost
solution, but is not guaranteed to find it in any reasonable amount of
time.
The A* search technique combines being "guided" by knowledge about
where good solutions might be (the knowledge is incorporated into the
Estimate function), while at the same time keeping track of how
costly the whole solution is.
One domain in which it is possible to find an estimate function that
satisfies the requirement above happens to be the driving domain. The
straight-line distance between two points will always be less than or
equal to the distance it actually takes you to drive between those two
points. And in fact A* was designed to find optimal solutions to
navigation problems. But there are other domains in which heuristic
estimate functions that satisfy the above constraint can be found, and
A* has been applied to them also.
There are lots of other ways to organize searches that incorporate the
above ideas. In general, the best search technique to use depends on
the domain you are working in.
Beam Search
The idea of a "beam search" is to only keep a fraction of the total
queue. The idea is that you just keep around those states that are
relatively good, and just forget the rest. This is a sort of
expansion of hill-climbing: instead of just keeping one state around,
you keep several. This can avoid some local optima, but not always.
It is most useful when the search space is big and the local optima
aren't too common. (The "genetic algorithm" is sort of a beam
search.)
Two-Way Search
In this technique, you make two separate searches, one from the
initial state forwards towards the solution, and the other from the
solution backwards towards the initial state. Any of the techniques
above can be incorporated, except that now you have two searches, and
you want to bring them together. If you have a way to estimate the
distance between two states, you can now choose to expand those states
which are closest to each other. Even with no heuristics, two way
search can be faster than Breadth-First search, because of the
exponential growth of the search space.
As I discussed before, the size of the search space grows roughly as
2n where n is the depth of the space (and there are only two
operators), and the total number of nodes in the space up to that
level is 2n+1-1.
So to find a solution that requires the application of 4 operators, a
total of 31 states might have to be examined by a Breadth-First
search.
On the other hand, two Breadth-First searches, that meet halfway,
would each have to examine just 7 states, for a total of 14 states.
As the solutions get longer, the ratio between the number of states
explored by a single one-direction search, and two Two-Way searches
decreases rapidly, and so this is a good idea if the domain is such
that it can be applied.
Island Search
The idea of "Island Search" is to first locate intermediate states
that you know will be part of the final solution, and then search
between those states. If there are enough such islands, the search
between them will be relatively short and easy. The islands might be
found by another search process, in a more abstract space. For
example, you might first find a solution that involves steps like
"remove muffler bearing", "install generator". Once you have found such a
solution, you can then figure out how to do the tasks. This approach
works well when the operators can be separated -- when doing one
doesn't affect the results of many others.

![[Top of page]](heuristic_files/big-top.gif)