Future Architecture of microprocessors
trend by year 2010
multi-media workload
architectural trend
trace cache
hybrid branch
prediction
advanced superscalar
super speculative
simultaneous multi-thread
trace processor
vector IRAM
one chip multi processor
RAW
conclusion
Billion transistors chip (mostly from IEEE Computer, Sept.
97)
Forecasting technology is full of errors.
-
"Everything that can be invented has been invented". US Commissioner of
Patents, 1899.
-
"I think there is a world market for about five computers". Thomas J Watson
Sr., IBM founder, 1943.
-
"There is no reason for any individuals to have a computer in their home".
Ken Olsen, CEO of Digital Equipment Corp., 1977.
-
"The current rate of progress can't continue much longer. We're facing
fundamental problems that we didn't have to deal with before". Various
computer technologists, 1995-1997.
Trend by year 2010
Wire delay becomes dominant, forcing hardware to be more distributed (limits
any centralized clock). A compiler is getting better at exploiting
parallelism hence, it can be rely on to build the future architecture.
Workloads contain more parallelism (multi-media workload). The design
and validation cost become more limiting factor.
-
The chip 800 M tr., 1000 pin, 1000 bit bus, 2G clock, 180W power
-
On chip wire is much slower than logic gates. A signal across the
chip may require 20 clocks.
-
Design, verfication and testing will consume large percent of cost.
-
Intel validate and test is 40-50% of design cost and in term of transistors
(built in test) is 6%.
-
Fabrication facility is now $2 billion, 10X more than a decade ago.
Multi-media workload
-
peer-to-peer
-
real-time
-
continuous data stream
-
vectors of packed 8- 16- 32- or FP size of operand
-
fine grain data parallelism : many elements with the same processing (filtering,
transformation), SIMD (vector), different from superscalar
-
coarse grain parallelism : multi-thread : encode/decode video audio simultaneously,
temporal/spatial parallel
-
high instruction reference locality to small loops : hand optimized is
practical
-
high memory bandwidth : cache not effective, requires data prefetch and
cache bypass
-
high network bandwidth : ISA towards real-time bitstream processing
Architecture Trend
Range of different architecture are from a more traditional design : scaling
up of today superscalar to a non-conventional design : using reconfigurable
computing arrays. The more traditional designs employ some recent
advance concept such as trace cache and multiple branch predictors to improve
the performance of instuction issued. The non-conventional designs
rely on the combination of compiler and hardware to extract more parallelism
from programs.
(from top to bottom : hardware more distributed as wire delay dominate,
and programming model is furthur depart from the norm)
-
advanced super scalar (16-32 inst./cycle)
-
super speculative (wide issue speculating)
-
simultaneous multi thread SMT (multi task, aggressive pipeline)
-
trace (multi scalar) (high ILP separate trace)
-
vector iram (vector + IRAM)
-
one chip CMP (4-16 processors)
-
Raw ( > 100 processing elements reconfigurable)
Grouping by concept will be :
-
advanced super scalar, super speculative : use wider instruction
issues
-
SMT, Trace : exploit multi-thread
-
V-IRAM : incorporate on-chip memory, use vector units
-
CMP : multi processors on a chip
-
RAW : reconfigurable hardware
Trace cache
is a I cache, the main purpose is to fetch past a taken branch. The
trace cache is access using the starting address of the next block of instructions.
It stores logically continuous instructions in physically continuous storage.
A cache line stores a segment of the dynamic instruction trace -- upto
an issue width -- across multiple taken branches.
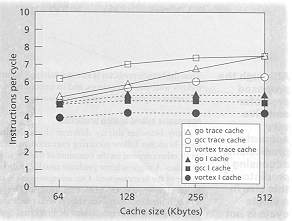
Figure The effect of trace cache continue to gain when the size
is increased
Hybrid branch prediction
Instead of using one kind of branch predictor, using several predictors.
Each targeting different classes of branches. It has advantage that
the warm-up time will be shorter (as each predictor is smaller), hence
it reacts to change in a program faster. However, with the same amount
of resource, several predictors will each be limited in size. Sometime
the performance depends on critical size of the buffer of predictor.
Advanced super scalar (U. of Michigan)
The main idea is : bigger, faster, wider (instruction issued).
The key problems are
-
instruction supply
-
data memory supply
-
implementable execution core
The solution :
to improve instruction supply :out-of-order fetch, multi hybrid branch
predictor and trace cache
to improve data supply : replicate first level cache, huge on chip
cache and data speculation
It will required a large out-of-order instruction window (2000) and
banks of functional units.
-
uniprocessor,
-
large trace cache
-
large number of reservation stations
-
large number of pipeline functional units
-
sufficient on chip data cache
-
sufficient resolution and fowarding logic
-
16-32 inst. per cycle
-
reservation station 2000 inst.
-
24-48 pipe line functional units
-
most important : inst. bandwidth, memory bandwidth and latency
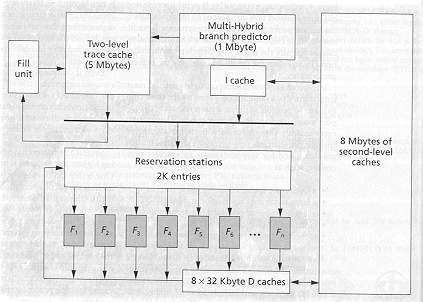
Figure The advanced super scalar
Super Speculative (Carnegie Mellon University)
super scalar has diminishing return.
state of the art processors : DEC Alpha 21264, Silicon Graphics MIPS
R 10000, PowerPC 604, Intel Pentium Pro, aims 4 IPC , achieve 0.5-1.5 for
real world programs.
Scaling a conventional superscalar will have a limit sustained IPC (see
fig the bars are 4-, 8-, 16-, 32- issues). Superspeculative attained
the sustained IPC ~ 10 for non-numerical programs.
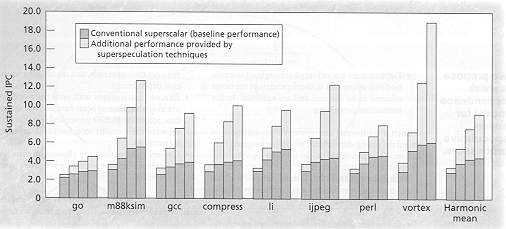
Figure Conventional superscalar don't scale up vs gain from superspeculative
Superflow :
instruction flow -- rate of useful instruction fetched, decoded and
dispatched
register data flow -- rate of which the results are produced
memory data flow -- rate of data store/retrieve from memory
Instruction flow is improved by using a trace cache. In
a trace cache : history based fetch mechanism, stores dynamic-instruction
trace in a cache indexed by fetch address and branch outcome. Whenever
it finds a suitable trace, it dispatches inst. from the trace cache rather
than sequential inst. from the inst. cache.
Register data flow : detect and resolve inter-inst. dependency
. Eliminate and
bypass as many dependencies as possible (mechanism such as register
renaming).
Mem. data flow : minimize average memory latency. Prediction
of load value, address.
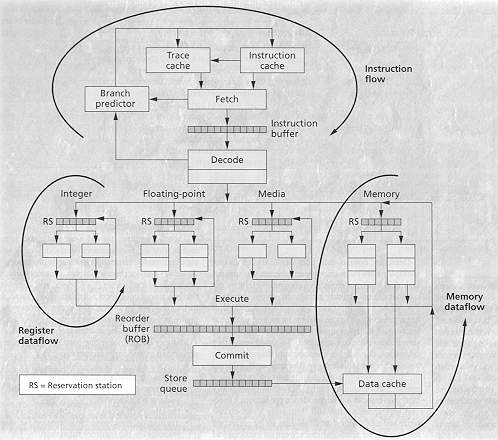
Figure Superflow architecture
Prototype (simulation)
-
fetch width 32 inst.
-
reorder buffer 128 entries
-
64 K 4-way set assoc. cache
-
128 K fully assoc. store queue
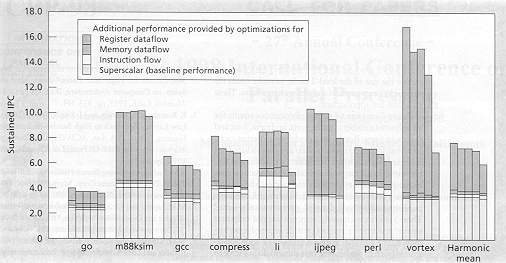
Figure performance : each bar prefect cache with unlimited
ports, 64K cache with unlimited ports, 64K with 8 ports, 64K with 4 ports,
64K with 2 ports) The cache with 64K 4 ports seems to be adequate.
Trace Processor (U. of Wisconsin at Madison)
Use multiple, distributed on-chip cores. Each simultaneously executes
a different trace. One core executes traces speculatively.
-
make parallel instructions more visible : must have a large instruction
window
-
dynamically partition hierarchical parallelism : replicated units,
control unit must allocate parts of program effectively
-
incorporate speculation for both control and data : control flow
-- branch prediction, data dependency -- speculation memory addressing
hazards
microarchitecture
instruction preprocessing : form a trace, check data dependency,
reordering, get resource.
trace cache
next trace prediction : predict multiple branches per cycle
instruction dispatch : register renaming, predict trace's input
data values, data speculation
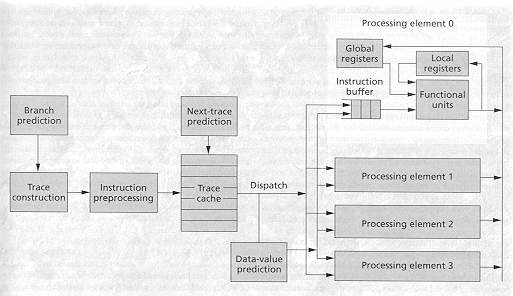
Figure each processor issues 4 inst/cycle. four pro. issue
16 inst/cycle, no benchmark result
Vector IRAM ( U. of California at Berkeley,
D. Patterson)
CPU speed up 60% per year, memory speed up 7% per year. The gap is
filled by cache memory. However large off chip and cache has
limit. Half area of Alpha chip is cache. MIPS R5000 compared to MIPS
R10000 (out of order speculative) R10K has 3.43 times more
area but performance gain only 1.64 (SpecInt95 rating)
The fact that DRAM can accommodate 30 to 50 times more data than the
same chip area devoted to caches (SRAM) so it should be treated as main
memory.. On chip memory can support high bandwidth (50 - 200 times)
, low latency (5 to 10 times) by using a wide interface and eliminating
the delay of pads and buses.
speed up by vectorization
SPECint95 42%
m88ksim 36%
PGP vector outperforms superscalar, vector uses only 10% die
area.
Advantage :
-
higher memory bandwidth
-
reduce energy (reduce off chip high capitance bus driving)
-
few pin, therefore can devote more pin to I/O (higher I/O bandwidth)
-
On chip mem. can reduce processor-memory latency 5-10 times and increase
bandwidth 5-20 times.
V-IRAM
-
vector unit : two load, one store, two ALU, 8 x 64 bit pipeline running
at 1 GHz
-
peak performance 16 GFLOPS or 128 GOPS when each pipeline is split
into multiple 8-bit pipelines for multimedia op.
-
on chip memory 96 Mbytes DRAM latency 20 ns, cycle 4 ns, will meet demand
192 Gbyte/s from vector unit
-
scalar core : dual issue with first level I&D cache.
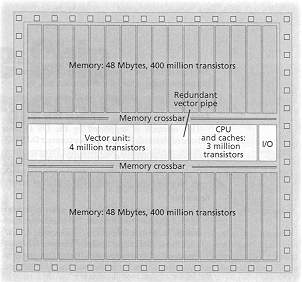
Figure Vector I-RAM
Simultaneous multi thread (SMT)
Augment wide superscalar to execute instructions from multiple threads
on control concurrently, dynamically selecting and executing instructions
from many active threads simultaneously. To run multi-thread, it
is required to save process states, e.g. Program counter, Registers.
There are 8 duplicated unit for PC and Registers.

Figure SMT
One chip multiple processors CMP (Stanford)
multiple (16) simple, fast processor. Each couples to a small, fast
level-one cache. All processors share a larger level-two cache.
-
Simple design
-
Faster validation
-
Code explicitly parallel
exploiting parallelism
-
in a single application : instruction level parallelism, data-independent
loop iteration : loop level parallelism. These two factors :
instruction window size
-
thread-level parallelism : A compile can simulate a single
large instruction window by multiple smaller instructio windows -- one
for each tread.
-
process-level parallelism (coarse grain) : independent applications
running in independent processes controlled by OS.
-
exploit parallelism, ILP, TLP, PLP (process)
-
multiple issue parallelism limits by instruction window size
-
layout of chip will affect architecture : avoid long wire
advantage :
-
area/complexity is linear vs quadratic in superscalar
-
shorter cycle time because short wire and no bus switch etc.
-
easier (faster) to design, verify and test
-
distributed cache lower demand on memory bandwidth
disadvantage
it is slower than SMT when running code that cannot be multithreadd,
because only one processor can be targeted to the task.

Superscalar
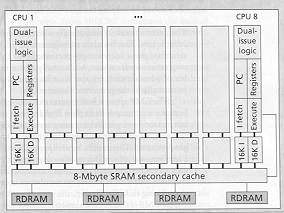
CMP
Figure Comparing superscalar, SMT and CMP under similar resource
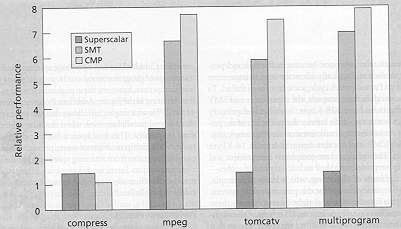
Figure Performance comparison
Raw (MIT)
Highly parallel, hundreds of very simple processors coupled with small
on chip memory. Each processor has a small bank of configurable logic.
It does not use ISA. A program is compiled to hardware. The
compiler schedules communication. Limit by compiler. Whether
this type of architecture is effective for the future workload is remained
an open question.
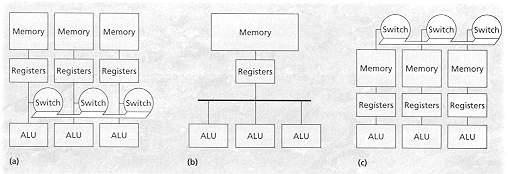
Figure Comparing RAW (a) with superscalar (b) and multi processors (c)
-
replicate tiles, interconnect is synchronous and direct, short latency.
-
static scheduling, operands are available when needed. eliminate
explicit
-
synchronization.
-
each tile supports multi granular (bit, byte, word : level ) operations.
-
1 billion tr. can make 128 tiles (5 M tr. each)
-
16K bytes inst. RAM ( static
ram)
-
16K bytes switch mem. (static ram)
-
32K first level data mem. (static ram)
-
128K DRAM
-
interconnect 30% of area
-
switch : single cycle message injection and receive operations. communication
nearly same speed as register read.
-
switch control : sequencing routing instruction.
-
configurability : at a coarser grain than FPGA, compiler can create customised
instruction without using longer software sequences (example, Game of Life
a custom instruction reduces 22 cycles to one)
-
Compiler is complex.
-
N tiles as a collection of functional units for exploiting ILP.
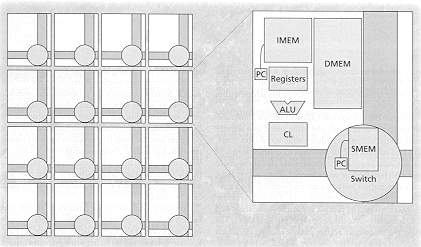
Prototype : 64 Xilinx 4013 FPGA (10,000 gates each) 25 MHz
speed up compared to Sun Sparc 20/71
Life 600 X : +32X bit level, +32X parallelism, +
22X configurability , -3X slow FPGA clock, -13X communication overhead.
Benchmark
Hardware prototype 25 MHz (Xilinx 4013) compares to software executing
on 2.82 SPECint95 SparcStation (Sparc 20/71)
| Benchmark |
data width (bits) |
no. of elements |
speed up over sw |
| binary heap |
32 |
15 |
1.26 |
| bubble sort |
32 |
64 |
7 |
| DES encryption |
64 |
4 |
7 |
| integer FFT |
3 |
4 |
9 |
| Jacobi 16x16 |
8 |
256 |
230 |
| Conway's life |
1 |
1024 |
597 |
| integer matrix mul |
16 |
16 |
90 |
| merge sort |
32 |
14 |
2.6 |
| n queens |
1 |
16 |
3.96 |
| single-source shortest path |
16 |
16 |
10 |
| multiplicative shortest path |
16 |
16 |
14 |
| transitive closure |
1 |
512 |
398 |
Conclusion
The rate of progress is very fast, the radical models of architecture that
will be dismissed a few years ago are now feasible. It is interesting
to explore the trends that will affect future architectures and the space
of these architectures. On-chip transistor budgets will soon allow
virtually anything to be implemented -- the limit will be mainly the designer's
imagination.